|
 |
|
ИЗ ПЕСНИ ... НЕ ВЫКИНЕШЬ Д. Ю. МАНИН Аннотация 1. Введение В «Структуре художественного текста» Ю. М. Лотман выдвинул стройную и привлекательную теоретическую концепцию. Нельзя, однако, не признать, что она носит несколько умозрительный характер. Хотя Лотман пользуется терминами математической теории информации, говоря об информативности, энтропии, коде, избыточности, но употребляются эти термины скорее метафорически, чем терминологически. Это не упрек: почти никаких точных данных, на которые можно было бы опереться в подобных построениях, до сих пор не существовало. Цель настоящей работы — хотя бы отчасти восполнить этот пробел, предоставив теоретикам островок твердой почвы под ногами. Плодотворность точных методов в литературоведении в настоящее время не должна вызывать сомнений. Б. И. Ярхо [1] и М. Л. Гаспаров с соавторами (см., напр., [2]) продемонстрировали, как это можно делать. Ярхо связывал «точные методы в литературоведении», в первую очередь, со статистическим анализом текстов. Так, в новаторской работе о трагедиях и комедиях Корнеля он нашел 15 формальных признаков (таких, например, как средняя длина реплики), которые прекрасно коррелируют с авторским определением жанра пьесы. Мало того, рассмотрев отдельно пьесы, в которых интуитивное жанровое ощущение неоднозначно («героические комедии», например), он обнаружил, что его показатели находятся в согласии с этим ощущением. Спрашивается, зачем нужен показатель, который показывает то, что нам и так известно? Дело в том, что это только первая, хотя и фундаментально важная, стадия естественнонаучной работы. Методы статистического анализа текстов обычно попадают в категорию «математических», но во многих случаях они гораздо ближе по духу к методологии естественнонаучного исследования. Спросим: зачем нужен термометр, прибор, который показывает то, что нам и так известно — какой предмет горячее, а какой холоднее? Опустите левую руку в горячую воду, а правую — в холодную. Затем выньте и опустите обе в воду комнатной температуры. Она покажется левой руке холодной, а правой — горячей. Точно так же, действие одной и той же пьесы может показаться стремительным или затянутым, в зависимости от установки или воспитания зрителя. В лучшем случае, без термометра можно выстроить сравнительный ряд: эта кастрюля горячее той. Но на материале поэтики даже такие качественные утверждения легко могут быть оспорены. Дойдя до этого пункта, можно сказать, что ощущение «нагретости воды» чисто субъективное, и исследование на этом закончить. Но можно попробовать изобрести термометр. Например, физик замечает, что некоторые тела при нагревании расширяются. Пока это утверждение интуитивно и бездоказательно: ведь объективного критерия нагретости у нас нет. Не смущаясь этим, физик конструирует водяной термометр, который измеряет нагретость тел по тому, насколько расширяется вода в колбе. На первый взгляд, такое измерение впадает в порочный круг, но это не так. Имея термометр, можно проверить, что и другие тела расширяются при нагревании пропорционально температуре, измеряемой водяным термометром. А значит, можно построить еще и спиртовой и ртутный термометры. Если оказывается, что их показания согласуются друг с другом и с нашими ощущениями, мы получаем важный результат: оба они измеряют одну и ту же объективную величину, нагретость тела. Но этого мало. Водяной термометр пригоден только в ограниченной области температур: от точки замерзания воды то точки ее кипения. Спиртовой же работает и при более низких температурах, зато не достигает точки кипения воды. Но поскольку у них есть общий диапазон (от нуля до 80 градусов Цельсия), их показания можно согласовать друг с другом и растянуть диапазон измеримых температур. Далее физик обнаруживает, что температуру можно измерять и по другим признакам: электрическому напряжению в термопаре, свечению раскаленного материала. Работая таким образом, он научается измерять температуру самого Солнца, где уже речи быть не может о том, чтобы поверить показания термометра рукой. М. И. Шапир в послесловии к «Методологии точного литературоведения» Ярхо ([3], с. 894) пишет: «Ярхо, я думаю, избежал провала лишь потому, что обследовал пьесы, созданные в короткий исторический промежуток и действительно обладавшие характеристиками, которые ученый неправомерно обобщил до универсальных признаков драмы». Но это критическое замечание можно прочесть, вопреки намерению его автора, как «Ярхо избежал провала только потому, что правильно поставил задачу». Пользуясь нашей термометрической метафорой, можно сказать, что Ярхо сконструировал только один, водяной термометр. Действительно, он пригоден только в ограниченном диапазоне «температур». Но интуитивные понятия комичного и трагичного отнюдь не ограничены драмой Корнелевского периода. Успех Ярхо на этом небольшом материале дает надежду, что для другого материала тоже можно найти объективные признаки, измеряющие положение текста на оси «трагичности/комичности». Конечно, это будут другие признаки, но если получится согласовать два измерительных прибора на том материале, к которому оба применимы, то мы получим важный результат: оба они измеряют одну и ту же объективную величину, комичность/трагичность текста. А продолжая эту работу, может быть, удастся добраться и до «Солнца», т.е. измерить степень комичности/трагичности текстов (например, древних), по отношению к которым нашей интуиции мы доверять уже не можем. Эта картина может показаться совершенно утопической, но вспомним, что несколько из найденных Ярхо признаков имеют общий смысл большей «подвижности», «раздробленности» действия в комедии. Нетрудно представить себе, что другие формальные признаки, применимые, например, к роману или эпосу, будут иметь тот же общий смысл. Разве это не добавит нам понимания природы жанра? А обладая целым рядом подобных «измерительных приборов» для разных величин, можно изучать, как эти величины менялись во времени и пространстве, как они связаны друг с другом, и на этом материале выявлять закономерности следующих уровней. Бытует представление о том, что цель работы естествоиспытателя — построение всеобъемлющей математической модели явления (или «открытого класса явлений» [3]). Но это не так. В конечном счете мы стремимся к пониманию предмета, хотя и не знаем толком, что именно значит — понимать. Математические модели явлений выделяют в очищенном виде отдельные принципы их устройства и тем помогают добыть понимание. Но они не являются самоцелью. Равным образом, статистические подсчеты в поэтике, как и все другие методы, суть лишь средство понять предмет исследования. Обрисованная выше модель работы естествоиспытателя, конечно, не единственно возможная. Мы так подробно остановились на ней потому, что именно такова методологическая установка настоящей работы. В ней предпринята попытка квантифицировать некоторое интуитивное ощущение от художественного текста, в особенности стихов. Это — ощущение «слова на своем месте». Существует множество вариантов ответа на вопрос, чем художественный текст отличается от нехудожественного. Все они, по-видимому, так или иначе отмечают более тесную связь (вплоть до тождества) между планом выражения и планом содержания художественного текста. Таково определение поэтической функции языка по Р. Якобсону как направленности сообщения на самое себя. Таковы соображения Ю. Лотмана о семантизации всех элементов стихотворной формы. Эти и подобные формулировки, однако, едва ли можно квантифицировать. Разбирая конкретные произведения, можно доказывать, что грамматические формы (Якобсон) или фонетика стиха (Лотман) вступают в системные отношения с семантикой текста. Но во-первых, такие разборы оказываются не безоговорочно убедительны (ср. полемику Якобсона с его критиками в [4]), а во-вторых, что важнее, они не ведут к количественным результатам. Разумеется, это не лишает их самостоятельной ценности, но делает непригодными для интересующей нас здесь цели. Такие обобщенные теоретические формулировки появляются как результат размышления над непосредственным читательским и писательским опытом: ощущением «слова на своем месте». Можно найти, вероятно, десятки высказываний на эту тему у авторов самых разных эпох и стилей:
Вильям Блейк. Видение о Страшном Суде.
Хармс. Записные книжки. Книжка 38. Л. 3 [5].
Лотман. Структура художественного текста. Гл. 1 [6].
Колмогоров. Семиотические послания [7].
Якобсон. Постскриптум к «Вопросам поэтики» [4]. Но не является ли это знакомое каждому ощущение мифом, культурно-обусловленной фикцией? Разные тексты вызывают его у разных читателей в разной степени. Стоит ли за ним какая-нибудь объективная реальность, и если да, то какая и можно ли ее измерить? Ощущение «слова на своем месте» складывается из двух составляющих: неожиданности и незаменимости элементов текста. Обе они поддаются непосредственному измерению. Неожиданность означает, что пропущенное слово должно быть трудно угадать, а незаменимость означает, что из двух вариантов должно быть легко выбрать «правильный», т.е. авторский. Эта идея легла в основу описываемого здесь эксперимента. Он реализован в виде сетевой литературной игры, где участникам предлагается угадывать слова в отрывках реальных текстов. Неправильно угаданные одним участником слова предлагаются другим как альтернативы авторскому слову (замены). Подробное описание методики следует ниже, а сначала мы очертим теоретическую парадигму, в рамках которой будут интерпретироваться результаты. 2. Информация и литература С самого зарождения математической теории информации исследователи стремились приложить ее к феномену художественной литературы. Уже в классической работе, заложившей основы теории [8], ее создатель Клод Шеннон писал:
Проблема, однако, в том, что математическая теория информации не дает способа измерять «семантическое содержание». Она создавалась для решения весьма практической задачи: сколько «информации» можно передать по данному кабелю в единицу времени и как увеличить это количество? Ясно, что для этого надо было сначала научиться измерять передаваемую «информацию». Шеннон предложил способ это делать: количество информации в сообщении он связал с неожиданностью этого сообщения для получателя. В одном предельном случае это определение согласуется с интуицией: если сообщение заранее известно, полностью предсказуемо, то оно не несет информации. Чем сообщение более неожиданное (т.е. чем меньше его априорная вероятность для получателя), тем больше информации оно несет. Однако в таком случае больше всего информации содержится в «сообщении», состоящем из случайного набора букв, оно самое непредсказуемое. Парадокс здесь только кажущийся. Чтобы в нем разобраться, полезно отвлечься от того, как измерять количество информации, и рассмотреть понятие плотности информации, количества ее в расчете, скажем, на букву. Если то же самое «содержание» передать более коротким текстом, то его плотность, очевидно, в этом тексте будет больше, чем в исходном. Программы-архиваторы, такие, как zip, именно так и устроены: сжимая текст, например, «Войны и мира», они преобразуют его в набор знаков, случайный на вид, и более короткий. Ясно, что как бы ни измерять «количество информации» в тексте «Войны и мира», в сжатом тексте оно останется таким же, а плотность ее возрастет. Примерно это и имеет в виду Шеннон, говоря о переводе Джойса на элементарный английский: количество информации при таком переводе осталось бы прежним, а плотность уменьшилась бы, потому что возрос бы объем. Но здесь возникает существенная трудность: отнюдь не очевидно, что «Поминки по Финнегану» в принципе возможно перевести на упрощенный язык без ущерба содержанию. Скорее, очевидно, что этого сделать нельзя. Именно поэтому математическую теорию информации невозможно строго применить к задачам филологии. До тех пор, пока под «содержанием» мы понимаем буквальный вид текста и занимаемся обратимыми преобразованиями текстов из одного формата в другой, кодированием и декодированием, не возникает вопроса о том, осталось ли «содержание», а стало быть, и его «количество» неизменным при преобразованиях. Как только мы переходим к возможности (или невозможности) разного выражения одного и того же содержания, критерии становятся крайне размытыми, а теорию информации можно использовать лишь как суггестивную метафору (что, впрочем, отнюдь не бесполезно). Отсюда видно, какую важную роль играет понятие синонимии текстов, т.е. вопрос о том, выражают ли два разных текста одно и то же содержание. Естественный язык обладает огромными возможностями для перифразы. Одно и то же содержание можно выразить многими разными способами (в частности, это предложение можно рассматривать как перифразу предыдущего). Однако, по-видимому, художественный, особенно поэтический, текст разительно отличается от утилитарного отсутствием такой синонимии — ср. знаменитое замечание Льва Толстого о том, чтó он хотел сказать «Анной Карениной». Ощущение слова на своем месте, о котором говорилось выше, также следует понимать в том смысле, что замена слова приводит (в идеале, конечно), к изменению содержания, а не к другому («худшему») выражению того же содержания. Лотман [6]:
Ср. аналогичное замечание из современного американского курса поэтики [9]:
Но куда деваются перифрастические возможности языка, когда речь заходит о художественных текстах? Почему от исчезновения синонимии «расширяется смысловая емкость языка»? Одна из задач настоящей работы в том, чтобы попытаться ответить на эти вопросы, придав соответствующим понятиям более точный смысл. Другой аспект проблемы художественного текста связан с ролью формальных ограничений в поэзии — метра, рифмы и т.п. В ряде неопубликованных работ, популяризованных Лотманом в [6] (см. также [7]), А. Н. Колмогоров развивал теоретико-информационный подход к этому явлению, основанный на представлении о том, что поэт как бы выбирает среди всех возможных текстов, выражающих данное содержание, те, которые дополнительно удовлетворяют необходимым формальным требованиям. Рассмотрим для иллюстрации множество всех возможных комбинаций букв, например, не длиннее «ВиМ». Это очень большое, но конечное число. Какая-то небольшая часть среди них будет грамматически правильными осмысленными русскими текстами. Разобьем их все на классы эквивалентности по синонимии, так что в каждый класс попадут взаимозаменяемые тексты, которые значат одно и то же. Иначе говоря, каждый такой класс будет выражать некоторое содержание, отличное от содержания других классов, причем выражать всеми возможными способами. Тогда количество синонимических классов даст нам количество смыслов, которые можно выразить текстом не длиннее «ВиМ», а среднее число текстов в каждом классе — количество способов, в среднем, выразить любое данное содержание. Первая величина (точнее, ее логарифм) отражает «энтропию смысловой емкости» языка, а вторая — «энтропию гибкости языка». Если энтропия гибкости достаточно велика, т.е. данное содержание может выражаться достаточно большим числом способов, то можно надеяться что, среди них найдутся и варианты, удовлетворяющие формальным ограничениям поэзии. Такой подход, однако, связан с серьезными проблемами. Сам термин «(формальные) ограничения» предполагает сужение пространства возможностей. Но это, в свою очередь, означает понижение неожиданности, а вместе с ней и информативности, даже если понимать ее только метафорически. В небольшой, но содержательной [10] Р. Абернати отмечает как парадокс, что «поэзия использует сокращенный и обедненный по сравнению с повседневной речью язык». Абернати предлагает для разрешения этого парадокса приписать всем высказываниям языка некую субъективную вероятность и считать, что настоящие стихи обладают сильно пониженной вероятностью, т.е. повышенной неожиданностью, несмотря на суженное пространство возможностей, из которого они выбираются. К сожалению, это совершенно неконструктивный подход, поскольку непонятно, как приписывать высказываниям вероятности, а главное — почему особо низкая вероятность оказывается связана именно с выполнением неких формальных ограничений. Надо заметить, что, по-видимому, и сам Колмогоров не был удовлетворен таким подходом, отчего им и не было опубликовано никаких работ на эту тему. В недатированной рукописи [11], впервые опубликованной В. А. Успенским в [12], он отмечает, что «В стихах допускается несколько более свободное пользование необычным в прозе расположением слов, что несколько увеличивает показатель β» (показатель гибкости выражения). (Успенский в [13], примечание к п. 5.2, тоже признает, что даже «презумпция о том, что корпус текстов литературных составляет лишь часть корпуса текстов осмысленных» требует корректив и приводит в качестве контрпримера «Дыр-бул-щыл» Крученых.) Зато можно предположить, что именно эта неудовлетворенность послужила толчком к созданию алгоритмической теории сложности. Характерно, что в работе [14], заложившей основы этой теории, при обсуждении вероятностного подхода к количеству информации Колмогоров пишет о его проблематичности применительно, например, к тексту «Войны и мира», а затем, после введения понятия, ныне известного как колмогоровская сложность, отмечает: «такие величины, как “сложность” текста романа “Война и мир”, можно считать определенными с практической однозначностью». Лотман предлагает иной путь разрешения проблемы. Он говорит, что энтропия гибкости языка «преобразуется» для читателя в энтропию смысловой емкости:
Иначе говоря, по Лотману, ключевую роль здесь играет уже упоминавшееся исчезновение текстовой синонимии в поэзии. Однако, так же, как с пониженными вероятностями Абернати, непонятным остается происхождение этого эффекта и его связь с формальными признаками поэзии. Мало того, само его существование, по существу, остается неподтвержденной гипотезой, интуитивным суждением. Таким образом, даже из этого краткого обзора становится понятно, что измерение как неожиданности, так и «незаменимости» (несинонимичности) слов в тексте имеет прямое отношение к принципиальным вопросам устройства художественного текста. 3. Постановка эксперимента Поставленная нами задача измерения неожиданности слов в тексте очень близка к задаче измерения количества информации в нем (обычно говорят об энтропии, т.е. плотности информации в расчете на символ), поскольку математическая информация тоже есть мера неожиданности. Существует ряд работ, посвященных экспериментальному определению энтропии естественного языка. С практической точки зрения, эта величина важна, потому что дает теоретический предел степени сжатия текстов. Так, поскольку в русском алфавите приблизительно 32 = 25 букв (если не считать пробела и знаков препинания), максимальная энтропия текста, составленного из такого алфавита — 5 бит на букву. Если энтропия реального русского текста составляет, например, 1,25 бит на букву, то его теоретически можно сжать в 5/1,25 = 4 раза. Существующие программы-архиваторы сжимают тексты на естественном языке всего примерно вдвое, и улучшение этого показателя — заманчивая задача для исследователя. Оценки энтропии важны и для таких приложений, как автоматическое распознавание речи. Первым, кто применил методы теории информации к исследованию свойств текстов на естественном языке, был сам основатель теории Клод Шеннон в классической работе 1951 года [15]. Он провел эксперименты, в которых респонденту предлагалось угадывать следующую букву в случайно выбранных отрывках из биографии президента Джефферсона (очевидно, текст литературный, но не образцово художественный). По результатам эксперимента Шеннон оценил энтропию литературного английского в пределах 0,6–1,3 бит на символ, что в 3–7 раз меньше, чем для последовательности, в которой те же буквы случайно перемешаны. Впоследствии ряд авторов повторяли эксперименты Шеннона с различными модификациями. Фонодь, работа которого [16] была популяризована Лотманом, сравнил угадываемость следующего символа в трех типах текстов: стихах, газетной статье и «разговоре двух девушек». Методика эксперимента в этой работе была, по-видимому, упрощенной (каждая буква угадывалась только один раз, а не до правильного ответа), что не позволяет по полученным результатам вычислить оценки энтропии по Шеннону. Однако вывод о том, что в стихах на 100 фонем угадывались лишь 40, в газетной статье — 67, а в телефонном разговоре двух девушек — целых 71, свидетельствовал в пользу повышенной энтропии в поэзии. С другой стороны, Фонодь отмечает, что ритмическая и фоническая (аллитерация, ассонанс, рифма) упорядоченность, казалось бы, действует в противоположном направлении, снижая непредсказуемость, а с ней и энтропию, и делает вывод о том, что оба явления можно свести к одному и тому же «принципу экономии». Другие оценки энтропии естественного текста, как с использованием экспериментов типа Шеннона, так и методами статистического анализа текстов, можно найти в [14, 17–23]. В некоторых из этих работ делались попытки связать теоретико-информационные характеристики текстов с их стилем и художественностью. Однако в основном подобные исследования мотивированы практической задачей оптимального сжатия текстов. Отметим единственное, по-видимому, методическое исследование зависимости энтропии от стиля, времени написания и автора [18], где материалом служили 39 английских переводов 9 греческих текстов, но использовалась весьма грубая методика оценки энтропии (по частотам двухбуквенных сочетаний). В отличие от всех работ этого направления, где текст угадывался последовательно по одной букве, в нашем эксперименте, в соответствии с поставленными задачами, респондентам предлагалось угадывать целое слово, выпущенное из середины контекста. Во-первых, минимальной единицей текста служит, конечно, слово, а не буква: даже при угадывании текста побуквенно люди в большинстве случаев основывают свой выбор на догадке о текущем слове. Во-вторых, даже обыкновенный текст не является простой последовательностью букв или слов, а пронизан синтаксическими и смысловыми связями между удаленными элементами. Стихи же и подавно представляют собой самосогласованные структуры, которые не читаются и тем более не пишутся последовательно. Эксперименты совсем другого рода, мотивированные непосредственно задачами филологии, проводились А. М. Пешковским [24], который анализировал искусственно придуманные варианты авторских текстов с целью продемонстрировать, что они всегда «ухудшают» текст. Согласно Шапиру [3], «аналогичные проверки на уместность тех или иных лексем предлагала проводить Э. Риккерт» в книге [25]. Несмотря на близость мотивировки, наше исследование существенно отличается методологически. Во-первых, варианты текста не придумываются экспериментатором, а возникают как попытки респондентов восстановить авторское слово. Во-вторых, оценка вариантов производится не экспериментатором, а респондентами, в условиях, исключающих субъективность и пристрастность по отношению к тексту или автору. Наконец, мы не оперируем понятием «улучшения» или «ухудшения» текста, но спрашиваем только, можно ли отличить авторское слово от замены. Эксперимент организован в виде сетевой литературной игры. Респондентам предлагается зарегистрироваться, заполнив по желанию небольшую анкету. Зарегистрированным игрокам предлагаются задания трех типов:
Полный протокол игры сохраняется в базе данных. Неправильные ответы на задания типа 1 выдаются в заданиях типов 2 и 3 в качестве альтернатив авторскому слову. Алгоритм выдачи заданий сводится в основном к следующему:
Трудность задания при этом колеблется в очень широких пределах — от очевидных до «невозможных» (например, имя собственное во фрагменте совсем незнакомого прозаического текста). С точки зрения эксперимента, это необходимо — нам нужно полное покрытие. Но и с точки зрения игры это оказывается уместно: трудные задания подогревают интерес, а легкие служат чем-то вроде утешительного приза. Предполагается, что играющие в такую игру будут стремиться найти наилучшее (т.е. наиболее подходящее) возможное слово. Для того, чтобы дополнительно поощрить такое поведение, игрокам начисляются очки за правильный ответ: 10 очков за задание типа 1, 5 за задание типа 2 и 3 за задание типа 3. Для того, чтобы стимулировать поиск подходящего слова в «безнадежных» (самых интересных для нас, в некотором смысле) ситуациях, дополнительно начисляются очки за удачные замены: всякий раз, когда замена принята другим игроком за авторское слово, ее автор получает 3 очка (а когда не принята — теряет одно). Наконец, для того, чтобы не было выгодно выбирать только легкие задания, а трудные пропускать, за каждое задание, оставленное без ответа, с игрока снимается одно очко. Игра состоит из трех этапов. Набор текстов в первом этапе фиксирован, он содержит 3439 фрагментов в 34 категориях. Большинство категорий состоят из произведений одного автора, иногда и определенного времени (например, стихи из сборника Ахматовой «Вечер»). Некоторые категории — сборные, например, случайная выборка стихотворений с сайта stihi.ru, популярного места самопубликации преимущественно непрофессиональных авторов. Средняя длина фрагмента — 141 символ, что приблизительно соответствует одному четверостишию пятистопного ямба. Категории текстов в первом этапе отбирались с целью исследовать возможно более широкий стилистический диапазон и определить таким образом границы изменения измеряемых величин, т.е. набросать карту местности, прежде чем переходить к ее подробному изучению. Полный список категорий приведен в Приложении. Игроки, прошедшие до конца первый этап, получают доступ во второй и третий. Тексты во втором этапе отбираются экспериментатором, а в третьем — вводятся самими игроками. Третий этап, таким образом, в первую очередь, игровой, и его данные здесь рассматриваться не будут (впоследствии, впрочем, возможно привлечь к анализу и их). Набор текстов второго этапа продолжает пополняться и преследует две основные цели:
По результатам игры вычисляются статистические характеристики: усредненные по категориям непредсказуемость и связанность, определение и свойства которых обсуждаются ниже. Анализ результатов в настоящей работе носит преимущественно статистический характер. Следует, однако, отметить, что поскольку сохраняется полный протокол эксперимента, данные допускают и другие уровни интерпретации с иными, чем здесь, задачами и методами. 4. Преимущества и недостатки экспериментальной методики 4.1. Репрезентативность и статистическая значимость Любое статистическое исследование обязано обеспечить объем материала, необходимый для статистической значимости результатов, и репрезентативность выборки. Репрезентативность выборки текстов в нашем случае определяется задачами исследования, и к ней формальные требования предъявить трудно. Ясно, что количество категорий должно быть «не слишком мало», однако указать минимально необходимое число едва ли возможно априори. Представляется, что полученные результаты показывают, что 34 категорий, представленных в первом этапе оказалось «достаточно». Другой аспект репрезентативности — количество фрагментов в категории. Надо учитывать, что поскольку общее число попыток (которое возможно набрать за реалистическое время) — основной лимитирующий фактор, увеличение общего количества фрагментов в эксперименте приводит к уменьшению числа попыток на фрагмент, т.е. повышение репрезентативности одновременно понижает статистическую значимость результатов и наоборот. Сто, в среднем, фрагментов на категорию — результат неформального компромисса между этими двумя требованиями. Отбор текстов в категории производился более или менее случайным образом, чтобы избежать влияния вкусов экспериментатора, которое было бы чрезвычайно трудно впоследствии учитывать. Грубая оценка показывает, что для статистической погрешности результатов в 1% по каждой категории необходимо иметь по 30000 попыток на категорию (по 100 попыток каждого типа на фрагмент), что примерно соответствует одному миллиону попыток в первом этапе. Чтобы достичь этого числа, скажем, за три года, надо набирать по 1000 попыток в сутки. Это совершенно немыслимые масштабы для традиционного лабораторного эксперимента, но вполне реальные для умеренно популярного сайта в интернете. Еще одна сторона репрезентативности — состав испытуемых. В отличие от лабораторного эксперимента, здесь он не поддается контролю. Однако и при наличии такой возможности ее было бы непросто использовать, поскольку чрезвычайно трудно формализовать требования к испытуемым. Неформально говоря, нас интересуют «внимательные» или «квалифицированные» читатели поэзии. При традиционной постановке эксперимента исследователь, вероятно, остановился бы на выборке студентов гуманитарных специальностей, что, вообще говоря, ничего еще не гарантирует. С другой стороны, в нашем случае сама ситуация литературной игры производит отбор участников более или менее в требуемом направлении. Случайные люди отсеиваются после относительно небольшого числа попыток. Наличие полного протокола позволяет постфактум отбирать для анализа подмножество данных по разным критериям, таким, как полное число попыток, сделанных участником. Оказывается, что этот показатель значительно сильнее коррелирует с успешностью игры, чем, например, тип образования. Наконец, сведения об участниках, собираемые в добровольной входной анкете, тоже позволяют оценить характер аудитории. Сюда входят частота сочинения и чтения стихов, уровень и тип образования, родной язык и язык повседневного общения. 4.2. Факторы систематической погрешности 4.2.1. Подглядывание Вероятно, самая очевидная проблема при постановке «открытого» эксперимента — проблема подглядывания. Значительная часть текстов игры имеется в сети в электронном виде и находится с помощью поисковых машин. Некоторые тексты, кроме того, некоторым испытуемым известны. Ясно, что это обстоятельство необходимо учитывать по крайней мере двумя способами: понимать, насколько сильно и в какую сторону это может повлиять на результаты, и уметь, насколько возможно, отсортировывать это влияние. С одной стороны, очевидно, что бороться с подглядыванием теоретически невозможно. С другой стороны, смысл и интерес самой игры для игрока, в первую очередь, (а для многих и вовсе) не в том, чтобы набирать очки, а в том, чтобы проверять и упражнять свои способности. Поэтому за редчайшими исключениями те, кто играет много, играют честно. А именно такие игроки нас и интересуют, как уже отмечалось. Для тех случаев, когда фрагмент игроку знаком или ответ подсмотрен в качестве исключения, игрок отмечает это обстоятельство при ответе на задание. Чтобы не наказывать за честность, мы не учитываем знакомость текста при подсчете очков, но в статистику эксперимента такие ответы не включаются. Если игрок систематически подглядывает ответ и не отмечает знакомость фрагмента (если такие случаи есть), у нас есть возможность определить и отсеять результаты такого игрока. Дело в том, что на результативность замен (т.е. на то, как часто другие игроки принимают их за авторские слова) подглядывание, очевидно, не влияет. Между тем, чем лучше человек угадыает пропущенные слова, тем лучше у него и замены. Значит, мы может отсеять результаты тех игроков, у которых успешность угадывания аномально велика по сравнению с успешностью замен. Наконец, можно сравнивать результативность игрока по текстам, имеющимся в сети, и отсутствующим. Конечно, все перечисленные методы не дают стопроцентной надежности, так что некоторое количество подсмотренных ответов попадет в статистику. Как они повлияют на результаты? Предположим для простоты, что частота подсматривания одинакова для всех типов задания и всех текстов. Это, конечно, не вполне верно, но для качественной оценки влияния достаточно. Пусть вероятность правильного ответа (без подсматривания) для некоторой категории текстов есть p в заданиях 1 типа и q в заданиях 3 типа. Пусть r — доля подсмотренных ответов. Тогда доля правильных ответов в заданиях 1 типа будет p' = r + (1−r)p а в заданиях 3 типа — q' = r + (1−r)q Соответственно, непредсказуемость U' составит U' = −log(r + (1−r)p) или, при r<<p приблизительно U' ≈ U − r/p где U — «истинное» значение. Поскольку реально p > 0.1, а r заведомо меньше этой величины (меньше, чем каждый десятый ответ подсмотрен тайно), это законное приближение. Таким образом, подсматривание снижает непредсказуемость тем сильнее, чем она выше, занижая разницу между категориями текстов. Иначе говоря, наши результаты по разнице в предсказуемости разных текстов следует считать оценкой снизу, консервативной. Опуская аналогичные вычисления для связанности, укажем лишь, что подсматривание действует на нее таким же образом. Это можно оценивать как положительный результат, поскольку нас интересует прежде всего разница в показателях разных текстов, и мы можем быть уверены, что систематическая погрешность эксперимента ее не завышает. 4.2.2. Безответственная игра Большая часть посетителей сайта, зарегистрировавшись и сделав несколько попыток, уходят навсегда, осознав, что им эта игра неинтересна. Многие из них оставляют в качестве замен бессмысленные сочетания букв, явные нелепости или вопиющие орфографические ошибки. Такие замены замечаются игроками и удаляются из игры. Существует и промежуточная категория замен, заведомо неправдоподобных для «квалифицированного читателя», но способных обмануть «наивного читателя». Такие замены мы оставляем, поскольку реакция на них тоже представляет интерес. Однако при этом надо понимать, как они влияют на статистику. В качестве модели предположим, что часть попыток сделана игроками, которые
p' = (1−r)p где p, p', q, q' имеют тот же смысл, что и выше. Анализ показывает, что результат получается таким же, как и в предыдущем случае: безответственная игра несколько нивелирует различия между категориями текстов. При этом для нас снова важно только то, что этот вид систематической погрешности не завышает разницы между категориями. 4.3. Фрагментированность текстов Одна из целей настоящей работы — собрать данные о связанности слова в тексте, степени его заданности и, возможно, уникальности. Связи, которыми определяется такая заданность (в той степени, в которой она действительно существует), многообразны по своей природе, силе и «дальнодействию» — от стандартной синтаксической структуры, действующей в пределах одного предложения, до интертекстуальных аллюзий и индивидуальных ассоциаций, известных одному автору или даже намеренно им зашифрованных. Мы изучаем кумулятивный эффект всех связей, не пытаясь, по крайней мере, поначалу, разделять влияние разных факторов (см., впрочем, ниже о «метрической связанности»). Разумеется, восприятие текста читателем не тождественно авторскому. Даже такие связующие факторы, как ритм и рифма, претерпевают индивидуальные вариации — так, «глубокие рифмы» Ахмадулиной воспринимаются как сильные связи одними читателями и как слабые — другими. При всем этом, однако, разбиение текста на короткие фрагменты неизбежно обрубает некоторые связи для всех читателей. В наименьшей степени при этом страдают короткодействующие связи (синтаксис, аллитерация, ритмика и т.п.) и самые дальнодействующие, такие, как отсылки к общекультурному контексту. В наибольшей степени затронутыми оказываются связи, действующие на масштабе одного конкретного текста, в первую очередь семантические. Попросту говоря, не зная, о чем речь, правильное слово во многих случаях найти невозможно. Это обстоятельство можно считать недостатком экспериментальной методики, однако оно же в принципе позволяет оценить роль таких внутритекстовых семантических (и стилистических, в той мере в какой они существуют) связей «среднего радиуса действия». Дело в том, что поскольку фрагменты предъявляются игрокам в случайном порядке, внимательный игрок постепенно собирает в уме образ текста из мозаики разрозненных фрагментов. Чем больше фрагментов текста было прочтено, тем лучше угадываются слова из оставшихся фрагментов — это экспериментальный факт. Разница между первым и последним фрагментами текста и дает некоторую меру силы указанных связей. 4.4. Диахронические эффекты Текст, в некотором смысле, не существует без читателя. Надо ясно понимать, что мы измеряем параметры не столько текста как такового, сколько системы «текст+читатель», параметры взаимодействия читателя с текстом. Ясно, что это взаимодействие с течением времени после написания текста претерпевает изменения. Так, хрестоматийная строчка Фета «Я пришел к тебе с приветом» воспринимается ныне совершенно не так, как для современников — и потому просто, что она стала хрестоматийной, и потому, что изменилась стилистическая окраска слова «привет» и возникла идиома «с приветом» (≈«чокнутый»), и потому, наконец, что она ныне участвует во множестве интертекстуальных связей с текстами, возникшими позже. Изменяется язык, репертуар художественных приемов, мзменяются читательские ожидания, на фоне которых и во взаимодействии с которыми функционирует текст. Однако в нашем распоряжении имеется только современный читатель, и на параметры его взаимодействия с текстами, написанными в разное время, влияет эта разница во времени, прямо учесть которую мы не можем. Это означает, что при сравнении между собой результатов по текстам разных эпох следует проявлять особенную осторожность в выводах. Это, пожалуй, все, что пока можно сказать. 5. Обзор экспериментальных результатов Мы рассматриваем экспериментальные результаты главным образом через призму двух параметров: непредсказуемости и связанности. Там, где не оговорено иное, речь пойдет о результатах первого этапа по данным на сентябрь 2007 года, когда в базе данных было чуть более миллиона попыток. 5.1. Непредсказуемость Непредсказуемость имеет смысл (отрицательного двоичного логарифма) вероятности угадать пропущенное слово в тексте, U = −log2 p1 Формально это определение совпадает с определением количества информации по Шеннону, но имеются два существенных отличия. Во-первых, в определении количества информации фигурирует вероятность угадать следующий элемент незаконченной последовательности, в то время как непредсказуемость подразумевает угадывание элемента, выпущенного из середины текста. Это важное отличие отражает представление о художественном тексте как явлении нелинейном, пронизанном связями во всех направлениях — как вперед, так и назад, а также (в стихах) по вертикали. Во-вторых, важно отметить, что для вычисления количества информации на слово следовало бы усреднять логарифмы вероятности угадывания по всем словам. Мы же усредняем сами вероятности (точнее, частоты), а затем берем логарифм от среднего, а это не то же самое. Среднюю энтропию слова можно интерпретировать как меру того, за сколько попыток можно отгадать наудачу взятое слово. Непредсказуемость же — это мера того, какова вероятность отгадать наудачу взятое слово с одного раза. В качестве наглядного примера рассмотрим хлебниковское двустишие «Бобэоби пелись губы / Вээоми пелись взоры». Слово «пелись» в обеих позициях будет угадано довольно легко благодаря отчетливому параллелизму. Вероятность же угадать несловарные слова бобэоби и вээоми крайне низка, и мы не слишком погрешим против истины, предположив, что она не выше 1/1000, что примерно соответствует 10 битам информации (210 = 1024). Тогда, ограничиваясь этими 4 словами, мы получим значение средней энтропии на слово в 5 бит (два слова по 10 бит и два слова почти по 0 бит). Непредсказуемость же будет всего 1 бит, поскольку вероятность угадать наудачу взятое слово составляет примерно 1/2 (два из четырех легко, другие два почти невозможно). Таким образом, непредсказуемость в нашем определении нечувствительна к тому, насколько именно трудно угадать трудно угадываемые слова, в то время как именно эти слова теоретически могут определить значение средней энтропии. Однако имеется серьезное препятствие к тому, чтобы вычислять энтропию по нашим данным: ни разу не угаданные слова дают частоту угадывания, равную нулю, а логарифм нуля — величина неопределенная. Эту трудность можно было бы обойти, произвольно положив энтропию ни разу не угаданных слов равной какой-нибудь константе. Были проведены проверочные подсчеты по такой методике с двумя значениями константы, в 3 и 10 бит. Обнаружилось, что она дает значения энтропии, практически монотонно зависящие от непредсказуемости. Поэтому мы предпочитаем в дальнейшем пользоваться непредсказуемостью, определение которой не содержит никаких произвольных допущений, понимая, что ее нельзя интерпретировать как энтропию, но имея в виду, что упорядочение текстов по непредсказуемости и по энтропии на нашем материале, вероятно, одно и то же. Непредсказуемость по нашим данным находится в относительно узком диапазоне от 0,8 до 2,2. В самой легкоугадываемой категории (тосты и поздравления к 8 марта) угадывается чуть больше, чем каждое второе слово, а в самой трудной (Введенский) — одно из четырех-пяти. Много это или мало — каждая пятая попытка? Рассмотрим протокол предъявления фрагмента одного из самых трудных текстов первого этапа, стихотворения А. Введенского «На смерть теософки»:
в траве лежала заграница стояла полночь а над нею вился туман земли темнее
Правильные ответы выделены шрифтом. Непредсказуемость, вычисленная только по этому фрагменту, составляет 2,67 +/− 0,4 (статистическая погрешность велика, поскольку относительно невелико число испытаний). Пожалуй, не приходится удивляться тому, что иногда угадываются слова «темница» (рифма, в семантическом поле ночи, тьмы) «лежала», «стояла», «туман» (вьющийся туман — поэтический штамп, к тому же фонетически поддержано заключительным рифменным словом), «земли». Несколько удивительнее угаданные слова «какое» и «заграница», но ничего невероятного и в этом нет. С другой стороны, у самого легкого (если не считать самодеятельных «тостов и поздравлений») автора, Николая Доризо, половина слов не угадывается. Так, в четверостишии
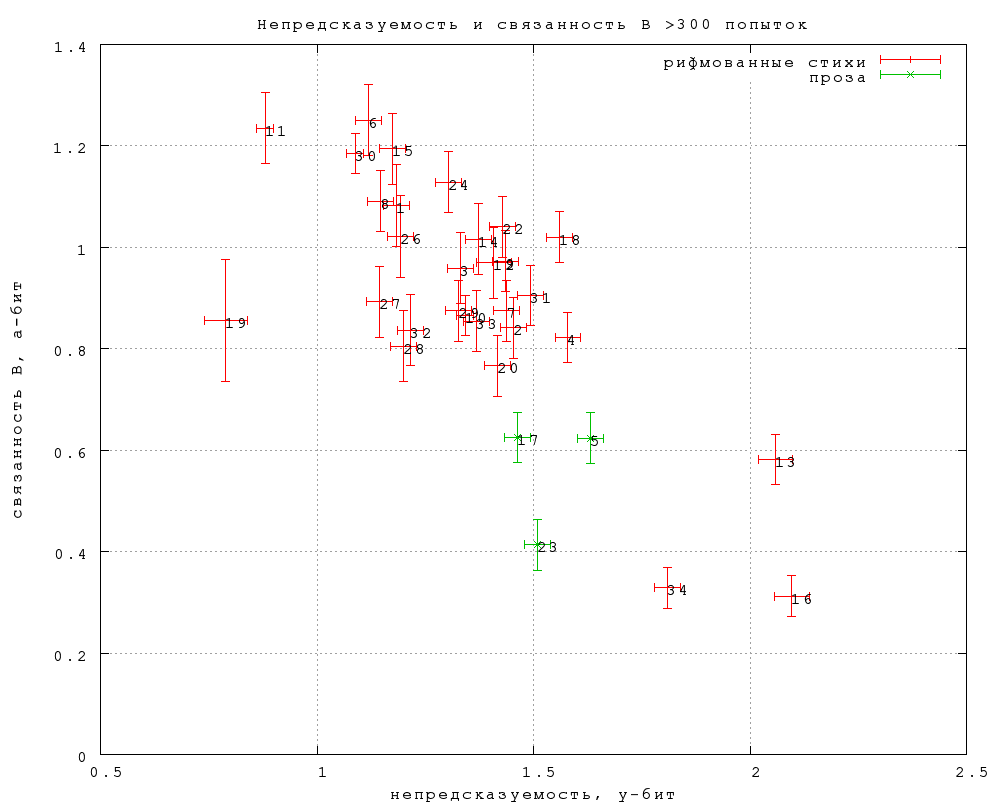
Тропинок много, но они не веха. Страсть - только вспышка. А любовь, Любовь, как мать, одна у человека. Когда сравниваешь эти два текста, напрашивается предположение о том, что непредсказуемость может иметь разную природу. Можно вообразить своего рода идеальный текст, в котором единственно возможное слово чрезвычайно трудно придумать, поскольку оно слишком уж неожиданное (гениально неожиданное), а можно (несколько легче) вообразить другой полюс, когда на данное место в тексте можно подставить десяток разных слов с одинаковым успехом. Оба, однако, будут иметь очень низкую предсказуемость. Разумеется, эти два полюса в чистом виде не реализуются, оба эффекта присутствуют в разных пропорциях в реальных текстах, и реально непредсказуемость не бывает ни очень низкой, ни очень высокой. Подавляющее большинство как стихов, так и прозы в первом этапе характеризуется непредсказуемостью в еще более узком диапазоне от 1,2 до 1,7. При этом характерно, что никакого водораздела между прозой и стихами по этому признаку не наблюдается. Почему? Как согласовать этот результат с интуитивным представлением о том, что стихи более насыщены содержанием, чем проза? Выше уже говорилось, что энтропия, то есть плотность информации, в естественном языке значительно меньше теоретического предела. Это свойство называется избыточностью. Избыточность необходима, потому что она придает коммуникации устойчивость к помехам. Так, рсскй ткст мжн прчсть дж псл длн всх глснх. Повышенная избыточность, очевидно, дает ключевое преимущество тексту, предназначенному для функционирования в таком «зашумленном канале связи», как устная традиция. Показательно, что простейший прием защиты от помех, — повтор, — одновременно является базовым и древнейшим поэтическим приемом. Формальные ограничения, такие как метр и рифма, повышают избыточность, но, по крайней мере, в поэзии нового времени, повышенная свобода обращения с языком в стихе действует в противоположном направлении. Наши данные показывают, что эти две тенденции почти точно компенсируют друг друга. Возможно, это следует считать свойством языка, который требует вполне определенного уровня избыточности — не слишком высокого и не слишком низкого. Но тогда возникает вопрос, зачем нужно одной рукой повышать избыточность, одновременно понижая ее другой. Мы вернемся к этому ниже, а сейчас рассмотрим второй показатель, связанность, по которому, как оказывается, стихи и проза существенно различаются. 5.2. Связанность В гипотетическом идеальном тексте, где «каждое слово должно быть обязательно» (Хармс) задания типа 3 на выбор правильного из двух слов должны угадываться стопроцентно верно, поскольку никакое слово, кроме авторского, не подходит. В предположении, конечно, об адекватности читательского восприятия (это отдельная идеализация). В гипотетическом «анти-идеальном» тексте, где каждое слово может быть без ущерба заменено на множество других, правильные ответы на задания типа 3 будут составлять вероятностные 50%. В соответствии с этой идеальной картиной мы определяем связанность B через долю правильных ответов на задания типа 3, p3, формулой B = log2(p3/(1-p3)) Если p3 = 0,5, связанность равна нулю, а при p3 стремящемся к единице связанность стремится к бесконечности. Чем легче в среднем отличить авторское слово от замены, тем выше связанность. Аналогично можно определить по крайней мере три других показателя связанности по результатам ответов на задания типа 2, когда дается только одно слово и предлагается определить, авторское ли оно. Оказывается, что результаты далеки от тривиальности, например, у того же Введенского авторские слова, предъявляемые в одиночку, с большим трудом опознаются как авторские (низкая связанность С), зато замены, предъявляемые в одиночку, опознаются легко (высокая связанность D). В этом обзоре мы ограничимся результатами по связанности B, подчеркнув лишь, что они не исчерпывают всей картины. На графике фиг. 1 категории текстов первого этапа изображены точками в координатах «непредсказуемость — связанность».
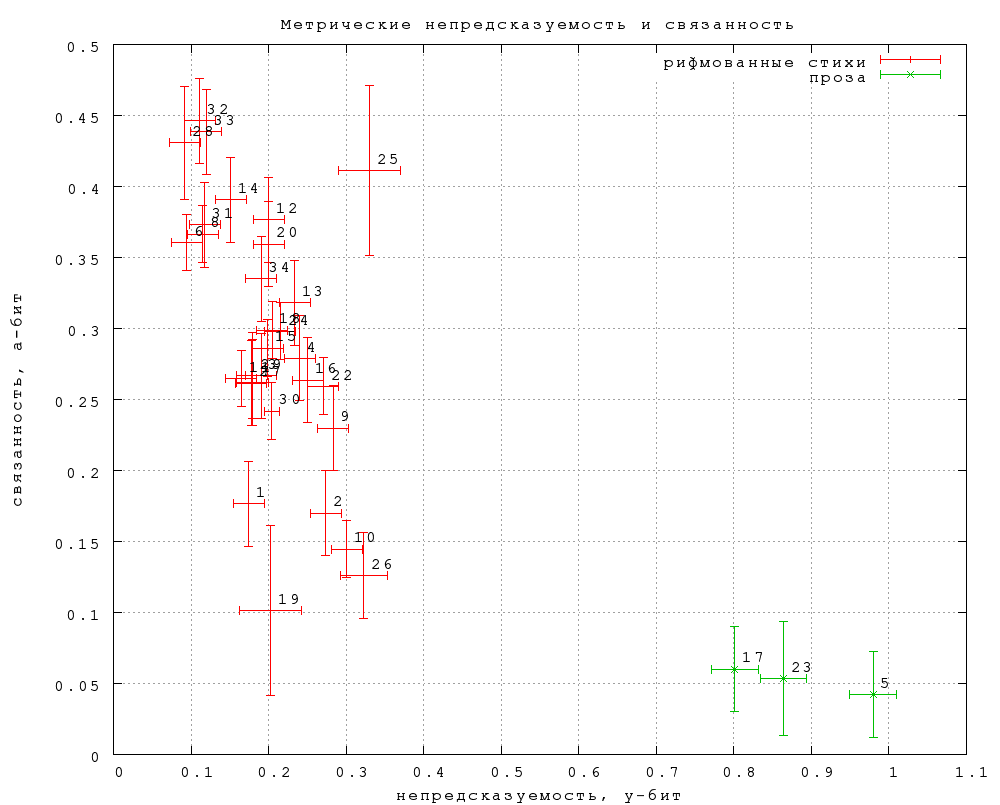
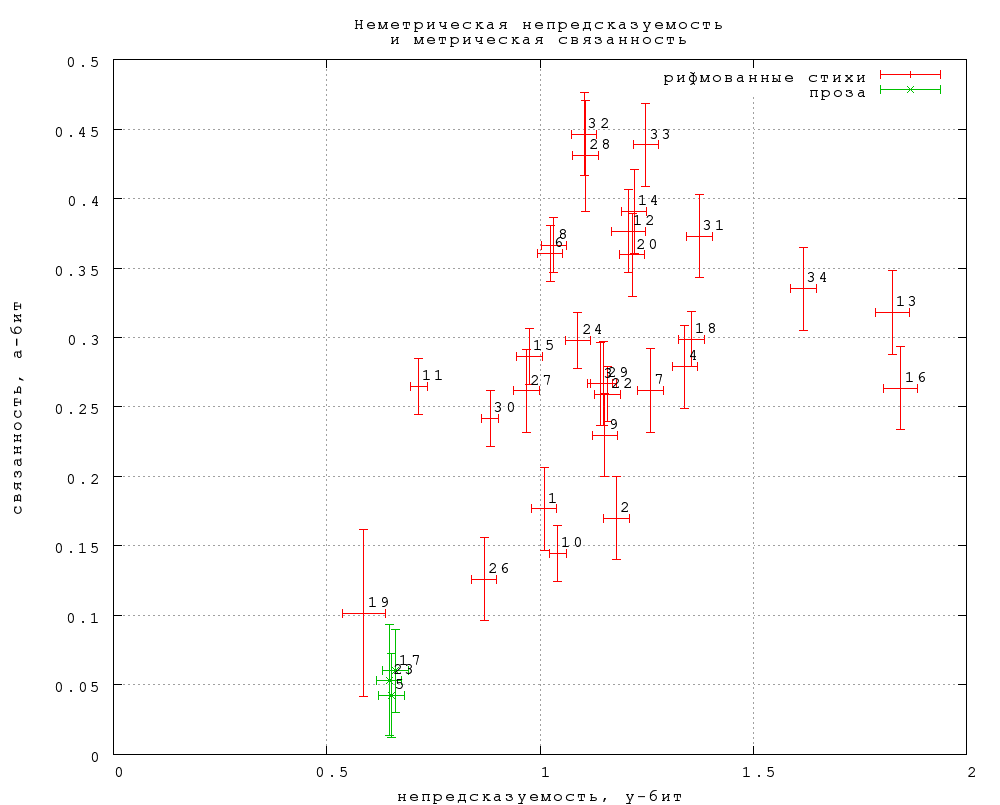
Прежде всего отметим, что, как и ожидалось, введение второй координаты — связанности — выявляет различия, которых нет в данных по непредсказуемости. Так, значительная часть стихов обладает примерно такой же, как и проза, непредсказуемостью, но существенно более высокой связанностью. С другой стороны, группа точек, соответствующих поэзии авангардного направления (Хармс, Введенский и Хлебников — точки 34, 16, 13), отличается от прозы повышенной непредсказуемостью при сравнимой связанности. Общая тенденция понижения связанности при повышении непредсказуемости вполне понятна: чем «труднее» текст, тем, вообще говоря, труднее и угадать в нем пропущенное слово, и опознать авторское. Но нас скорее интересуют отклонения от этой тенденции. Замечательно (и несколько неожиданно) здесь отчетливое отделение стихов от прозы: стихи должны обладать либо более высокой связанностью, чем проза (при такой же или несколько меньшей непредсказуемости), либо более высокой непредсказуемостью (при такой же или несколько меньшей связанности). Оговоримся, что в первом этапе нет или почти нет верлибра и белых стихов, а проза была отобрана по признаку максимальной, по мнению экспериментатора, «прозаичности» («Анна Каренина», «Доктор Живаго» и публицистическое эссе «Антикопирайт» М. Вербицкого). Исследованию форм, в разных смыслах промежуточных между рифмованными стихами и прозой, как уже говорилось, посвящен второй этап. Самым высоким значением связанности обладают сонеты Шекспира в переводе Маршака (точка 6). Для сравнения, переводы С. Степанова (точка 8) при такой же (в пределах статистической погрешности) непредсказуемости имеют значимо более низкую связанность. Две выпадающие точки с аномально низкой непредсказуемостью — тосты и поздравления (19) и стихи Н. Доризо (11). Последнее обстоятельство было бы соблазнительно интерпретировать в терминах «художественности» или «качества». Однако другие данные не допускают такой прямолинейной интерпретации. Так, точка 10 представляет поступления одного дня на сайт самопубликации при Библиотеке Мошкова, журнал «Самиздат» (http://zhurnal.lib.ru). Она лежит рядом со стихами Саши Черного (29) и Беллы Ахмадулиной (33), а также посередине между стихами Тютчева (28) и Баратынского (31). Тем не менее, любопытно отметить, что сумма непредсказуемости и связанности особенно высока у Пастернака (точка 18) и Хлебникова (13). Вероятно, именно высокую сумму этих двух величин можно считать некоторым приближением к интуитивному представлению о тексте, нарушающем опережающее читательское ожидание (непредсказуемость), но удовлетворяющем апостериорное ожидание (связанность). Отметим, что по данным М. Л. Гаспарова [26], именно у Пастернака наиболее высок показатель тропеичности (доля знаменательных слов, употребленных в небуквальных значениях). Интересно было бы сравнить показатель тропеичности с данными по непредсказуемости и связанности для нашей выборки текстов. Как в таком случае интерпретировать аномально низкую сумму U+B у стихов Тютчева и Фета (точки 28 и 32)? Для ответа на этот вопрос следовало бы перейти от статистического к более детальному изучению данных. Возможно, дело в том, что поэтическая ткань этих стихов воспринимается современным читателем как нечто само собой разумеющееся, поскольку тогдашние достижения ныне прочно вошли в основной репертуар грамотного стихосложения, а язык еще не приобрел «остранняющий» налет архаичности — отсюда относительно низкая непредсказуемость. С другой же стороны, попадающиеся время от времени неожиданности на этом фоне труднее воспринимаются как «обязательные», отчего понижается связанность. Иначе говоря, здесь могут сказываться упомянутые выше диахронические эффекты. Сходными причинами, вероятно, объясняется очень высокая сумма U+B у од Ломоносова — по предварительным данным второго этапа, такая же, как у позднего Мандельштама. При интерпретации этих данных не следует забывать, что они представляют собой проекцию пространства очень большой размерности на плоскость всего двух переменных. Так, если бы мы оперировали данными только по непредсказуемости, «Доктор Живаго» и стихи Цветаевой оказались бы на шкале в одном месте. Введя вторую координату связанности, мы увидели, что на самом деле эти точки лежат довольно далеко друг от друга. Аналогичным образом, если две точки лежат рядом на приведенном графике, это отнюдь не означает, что соответствующие тексты «одинаковы» — просто мы не измерили те параметры, по которым они различаются. Итак, наши результаты показывают, что ощущение «слова на своем месте» действительно имеет под собой объективную основу, и что стихи от прозы отличаются по этому признаку. Какими средствами это достигается — предмет дальнейших исследований. 5.4. Влияние стихотворного метра 5.4.1. Метрическая непредсказуемость Угадыванию слов в стихах должны, очевидно, помогать ритм и рифма. Тем не менее, у большинства традиционных, неавангардных стихов, непредсказуемость примерно такая же, как у прозы. На качественном уровне этот результат объясним известным эффектом расшатывания синтаксиса и семантики в стихе: повышению предсказуемости за счет метра противодействует ее понижение за счет более свободной сочетаемости слов. Однако теперь мы можем оценить масштабы этого явления количественно. Оставляя пока в стороне рифму, рассмотрим влияние стихотворного метра. Выделить его можно, если учесть слоговую длину замен в сравнении со слоговой длиной авторского слова (можно было бы учесть и ударения, но это по техническим причинам пока сделать трудно). Именно, определим метрическую непредсказуемость как отрицательный двоичный логарифм вероятности угадать только длину слова, но не обязательно само слово. Поскольку вероятность угадать слово равна произведению вероятности угадать его длину на условную вероятность угадать слово при известной длине, разность между полной непредсказуемостью и метрической дает неметрическую непредсказуемость, дающую оценку этой последней вероятности (напомним, что логарифмы складываются при перемножении их аргументов). Иными словами, неметрическая непредсказуемость характеризует вероятность угадать слово при условии, что его длина известна (уже угадана). С ее помощью можно сравнивать стихи и прозу, отвлекаясь от влияния стихотворного метра. Как видно из графиков фиг. 2 и 3, непредсказуемость прозы складывается из почти равных частей метрической и неметрической непредсказуемости (ок. 0,9 и 0,7 соответственно). У стихов же, как и ожидалось, метрическая непредсказуемость очень низка, от 0,1 до 0,3 (вероятность угадать длину слова от 81 до 93%) даже для категорий с большой пропорцией дольников (Цветаева), полиметрических (песни М. Щербакова) и непрофессиональных текстов (стихи.ру и «Самиздат»). Неметрическая часть непредсказуемости у всех стихов выше, чем у прозы, кроме «тостов и поздравлений», где она такая же. Напомним, что эта величина измеряет вероятность угадать слово, если его длина известна. Таким образом, в (метрических) стихах действительно значительно повышена свобода сочетания слов по смыслу и синтаксису, и это компенсирует пониженную свободу их сочетания по длине (и ритмическому рисунку, но таких данных у нас нет). Любопытно, хотя и не очень достоверно статистически, что вся разница в предсказуемости трех прозаических текстов первого этапа заключена в метрической непредсказуемости — остаточная часть у них точно одинакова при всей разнице эпох и стилей. 5.4.2. Метрическая связанность Ясно, что стихотворный метр оказывает влияние и на опознание авторского слова: в стихах должно быть заметно легче отличить замену от авторского слова, если она имеет другую длину. Меру этого эффекта для простоты определим как Bm = −log2(p3T/p3F) где p3T,F — вероятность правильного ответа в задании типа 3 (на выбор из двух) при правильной и неправильной слоговой длине замены соответственно. Эту величину мы будем называть метрической связанностью. Она показывает, насколько длина слова в отрыве от всего остального помогает определить авторское слово, иначе говоря, насколько автор оправдывает создаваемое им у читателя метрическое ожидание. Метрическая связанность, как и следует ожидать, много больше у стихов, чем у прозы. Замечательно, однако, что и у прозы она, хотя и маргинально, но значимо отлична от нуля. Значит ли это, что некое различимое ритмическое дыхание свойственно и художественной прозе, не претендующей на явную ритмичность? Самая высокая метрическая связанность у стихов 19 века (Тютчев, Фет, Жуковский), а также, неожиданно, у Ахмадулиной. Самая низкая — у непрофессиональных стихов, у песенных текстов Щербакова со сложной ритмикой и у ранней Ахматовой (сб. «Вечер»; в стихах Ахматовой 36–46 гг. метрическая связанность на среднем уровне). На графике фиг. 3 привлекает внимание тенденция к повышению метрической связанности при повышении неметрической непредсказуемости. Это значит, что чем свободнее синтаксическая, семантическая и прочая неметрическая сочетаемость слов, тем жестче становится читательское ожидание метрической упорядоченности. Этой тенденции, хотя и в несколько ослабленном виде, подчиняются даже авангардные стихи, во многих других отношениях резко отличающиеся от традиционных.
Таким образом, мы снова столкнулись с механизмом компенсации, когда повышение свободы текста в одних отношениях как бы сводится на нет ужесточением ограничений в других отношениях, понижение избыточности в одном месте компенсируется ее повышением в другом. Зачем это делается? Возможно, ответ следует искать в теоретико-информационной метафоре кода с коррекцией ошибок. Представим себе простейший код, в котором для надежности передачи по зашумленному каналу каждый символ просто повторяется дважды. Если в таком сообщении выпустить один символ, он восстанавливается со стопроцентной надежностью, то есть, не несет информации вообще. Зачем же он нужен? Он несет мета-сообщение: «в это сообщение не вкралось ошибок при передаче». Ощущение «слова на своем месте» в художественном тексте можно, таким образом, уподобить приему аналогичного мета-сообщения, только, скорее, не об отсутствии ошибок передачи, а о правильной расшифровке. Вспомним идею Лотмана [6] о том, что художественный текст одновременно передает сообщение и задает язык, на котором это сообщение закодировано. Если читатель чувствует, что слово на своем месте, это чувство говорит ему, что он правильно расшифровывает язык сообщения. Для этого в тексте обязана быть избыточность. Но поэзия, в отличие от прозы, может использовать для передачи мета-сообщения метр, а также рифму и другие формальные приемы, которые непригодны для передачи собственно сообщения. За счет смещения избыточности-предсказуемости в эти несемантические области она освобождает семантическую область текста для передачи смыслов, которые поэтому оказываются значительно более насыщенными. Таким образом, формальные ограничения парадоксальным образом повышают информативность (точнее, открывают возможность ее повышения, которая, конечно, может и не использоваться — тогда возникает «сплющенная ценность» вроде рифмованных тостов и поздравлений). Метр, аллитерация и другие виды внесемантической упорядоченности поэтического текста интерпретировались Якобсоном и Лотманом как несущие информацию, вплоть до присвоения семантики отдельным фонемам. По-видимому, более правильно будет модифицировать этот взгляд, сказав, что эти элементы мета-информативны. Тут нет противоречия — аллитерация, интерпретируемая по Лотману как несущая смысл, переинтерпретируется как несущая мета-информацию, т.е. помогающая удостовериться, что текст расшифрован правильно, если смысловые переклички согласуются со звуковыми. Теперь мы можем предложить и ответ на вопрос, заданный в начале: каким образом и почему энтропия выражения в поэзии превращается в энтропию содержания, почему в поэтическом языке отсутствует текстовая синонимия? По-видимому, на него нельзя ответить, оставаясь в рамках представления о некоем замкнутом множестве всех «допустимых» или «осмысленных и грамматически правильных» текстов языка, в котором стихи составляют подмножество. Но данные и не поддерживают это представление. В самом деле, если пониженная метрическая непредсказуемость стихов соответствует сужению пространства возможностей для стиха по сравнению с прозой, то повышенная неметрическая непредсказуемость означает компенсаторное расширение этого пространства в другом направлении, за счет ослабления, как уже говорилось, семантико-синтаксических ограничений на сочетаемость слов. Но это, в свою очередь, означает, что стихи не являются «осмысленными грамматически правильными» или «допустимыми» текстами базового языка, они выходят за его пределы (см. фиг. 4). Это — лишь оборотная сторона все той же лотмановской идеи о художественном произведении как тексте, задающем свой собственный язык. В той или иной степени общеязыковые законы заменяются в стихе отчасти общепоэтическими, отчасти же индивидуальными структурными связями. Но когда общеязыковые закономерности перестают действовать или хотя бы ослабляются, вместе с ними ослабляется и обусловленная ими общеязыковая синонимия текстов. 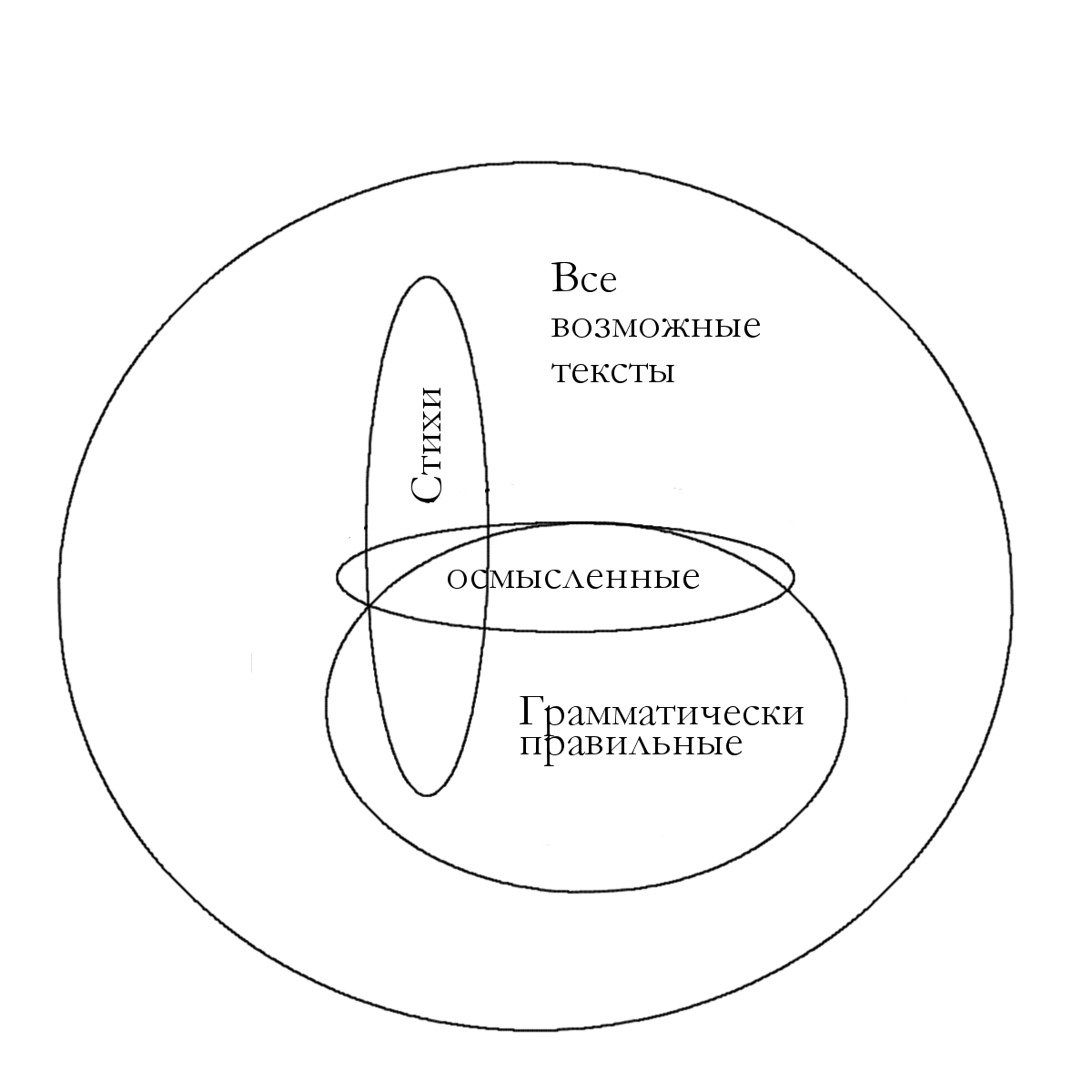
Возможно, одна из функций великой поэзии — расширение множества «допустимых текстов». «Для того, чтобы состояться, поэзии требуется выход за пределы языка, своеобразный экс-стасис» (поэт Марианна Гейде [27]). Приведем цитату, интересную как непосредственное (не опосредованное теоретическим мышлением) свидетельство того, что «выход за пределы языка» рождает для слушателя новый, невыразимый иным образом, смысл. Режиссер Т. Хейнз, снявший фильм о Бобе Дилане, комментирует песню Дилана, давшую название фильму [28]:
Заключение В предисловии к специальному выпуску журнала Computational Linguistics [29] авторы отмечают, что 90-е годы ознаменовались возрождением эмпирического подхода к анализу языка, первый всплеск которого пришелся на 50-е и который затем надолго сменился аналитическим (представленным такими исследователями, как Хомский и Минский). Это возрождение не в последнюю очередь было порождено бурным ростом вычислительных мощностей и объемов оцифрованных текстов. Но развитие вычислительной техники и компьютерных сетей предоставляет беспрецедентные возможности и для экспериментального исследования восприятия текста читателем. В настоящей работе мы представили лишь самые первые результаты обработки огромного и продолжающего расти массива данных. Но уже сейчас очевидно, какую роль может сыграть в развитии поэтики возможность строить гипотезы на твердом основании, предоставляемом экспериментом. Мы надеемся, что эти данные прочно войдут в арсенал средств исследователей наряду с количественными методами анализа текстов. ЛИТЕРАТУРА
ПРИЛОЖЕНИЕ Номера соответствуют номерам точек на графиках.
|